
Python’s built-in logging module is designed to give you critical visibility into your applications with minimal setup. Whether you’re just getting started or already using Python’s logging module, this guide will show you how to configure this module to log all the data you need, route it to your desired destinations, and centralize your logs to get deeper insights into your Python applications. In this post, we will show you how to:
- Customize the priority level and destination of your logs
- Configure a custom setup that involves multiple loggers and destinations
- Incorporate exception handling and tracebacks in your logs
- Format your logs in JSON and centralize them for more effective troubleshooting
Python’s logging module basics
The logging module is included in Python’s standard library, which means that you can start using it without installing anything. The logging module’s basicConfig() method is the quickest way to configure the desired behavior of your logger. However, the Python documentation recommends creating a logger for each module in your application—and it can be difficult to configure a logger-per-module setup using basicConfig() alone. Therefore, most applications (including web frameworks like Django) automatically use file-based or dictionary-based logging configuration instead. If you’d like to get started with one of those methods, we recommend skipping directly to that section.
Three of the main parameters of basicConfig() are:
- level: the minimum priority level of messages to log. In order of increasing severity, the available log levels are: DEBUG, INFO, WARNING, ERROR, and CRITICAL. By default, the level is set to WARNING, meaning that Python’s logging module will filter out any DEBUG or INFO messages.
- handler: determines where to route your logs. Unless you specify otherwise, the logging library will use a
StreamHandlerto direct log messages tosys.stderr(usually the console). - format: by default, the logging library will log messages in the following format:
<LEVEL>:<LOGGER_NAME>:<MESSAGE>. In the following section, we’ll show you how to customize this to include timestamps and other information that is useful for troubleshooting.
Since the logging module only captures WARNING and higher-level logs by default, you may be lacking visibility into lower-priority logs that can be useful for conducting a root cause analysis. The logging module also streams logs to the console instead of appending them to a file. Rather than using a StreamHandler or a SocketHandler to stream logs directly to the console or to an external service over the network, you should use a FileHandler to log to one or more files on disk.
One main advantage of logging to a file is that your application does not need to account for the possibility of encountering network-related errors while streaming logs to an external destination. If it runs into any issues with streaming logs over the network, you won’t lose access to those logs, since they’ll be stored locally on each server. Logging to a file also allows you to create a more customized logging setup, where you can route different types of logs to separate files, and tail and centralize those files with a log monitoring service.
In the next section, we’ll show you how easy it is to customize basicConfig() to log lower-priority messages and direct them to a file on disk.
An example of basicConfig()
The following example uses basicConfig() to configure an application to log DEBUG and higher-level messages to a file on disk (myapp.log). It also indicates that logs should follow a format that includes the timestamp and log severity level:
import logging
def word_count(myfile):
logging.basicConfig(level=logging.DEBUG, filename='myapp.log', format='%(asctime)s %(levelname)s:%(message)s')
try:
# count the number of words in a file and log the result
with open(myfile, 'r') as f:
file_data = f.read()
words = file_data.split(" ")
num_words = len(words)
logging.debug("this file has %d words", num_words)
return num_words
except OSError as e:
logging.error("error reading the file")
[...]
If you run the code on an accessible file (e.g., myfile.txt) followed by an inaccessible file (e.g., nonexistentfile.txt), it will append the following logs to the myapp.log file:
2019-03-27 10:49:00,979 DEBUG:this file has 44 words
2019-03-27 10:49:00,979 ERROR:error reading the file
Thanks to the new basicConfig() configuration, DEBUG-level logs are no longer being filtered out, and logs follow a custom format that includes the following attributes:
%(asctime)s: displays the date and time of the log, in local time%(levelname)s: the logging level of the message%(message)s: the message
See the documentation for information about the attributes you can include in the format of each log record. In the example above, an error message was logged, but it did not include any exception traceback information, making it difficult to determine the source of the issue. In a later section of this post, we’ll show you how to log the full traceback when an exception occurs.
Digging deeper into Python’s logging library
We’ve covered the basics of basicConfig(), but as mentioned earlier, most applications will benefit from implementing a logger-per-module setup. As your application scales, you’ll need a more robust, scalable way to configure each module-specific logger—and to make sure you’re capturing the logger name as part of each log. In this section, we’ll explore how to:
- configure multiple loggers and automatically capture the logger name
- use
fileConfig()to implement custom formatting and routing options - capture tracebacks and uncaught exceptions
Configure multiple loggers and capture the logger name
To follow the best practice of creating a new logger for each module in your application, use the logging library’s built-in getLogger() method to dynamically set the logger name to match the name of your module:
logger = logging.getLogger(__name__)
This getLogger() method sets the logger name to __name__, which corresponds to the fully qualified name of the module from which this method is called. This allows you to see exactly which module in your application generated each log message, so you can interpret your logs more clearly.
For example, if your application includes a lowermodule.py module that gets called from another module, uppermodule.py, the getLogger() method will set the logger name to match the associated module. Once you modify your log format to include the logger name (%(name)s), you’ll see this information in every log message. You can define the logger within each module like this:
# lowermodule.py
import logging
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s')
logger = logging.getLogger(__name__)
def word_count(myfile):
try:
with open(myfile, 'r') as f:
file_data = f.read()
words = file_data.split(" ")
final_word_count = len(words)
logger.info("this file has %d words", final_word_count)
return final_word_count
except OSError as e:
logger.error("error reading the file")
[...]
# uppermodule.py
import logging
import lowermodule
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s')
logger = logging.getLogger(__name__)
def record_word_count(myfile):
logger.info("starting the function")
try:
word_count = lowermodule.word_count(myfile)
with open('wordcountarchive.csv', 'a') as file:
row = str(myfile) + ',' + str(word_count)
file.write(row + '\n')
except:
logger.warning("could not write file %s to destination", myfile)
finally:
logger.debug("the function is done for the file %s", myfile)
If we run uppermodule.py on an accessible file (myfile.txt) followed by an inaccessible file (nonexistentfile.txt), the logging module will generate the following output:
2019-03-27 21:16:41,200 __main__ INFO:starting the function
2019-03-27 21:16:41,200 lowermodule INFO:this file has 44 words
2019-03-27 21:16:41,201 __main__ DEBUG:the function is done for the file myfile.txt
2019-03-27 21:16:41,201 __main__ INFO:starting the function
2019-03-27 21:16:41,202 lowermodule ERROR:[Errno 2] No such file or directory: 'nonexistentfile.txt'
2019-03-27 21:16:41,202 __main__ DEBUG:the function is done for the file nonexistentfile.txt
The logger name is included right after the timestamp, so you can see exactly which module generated each message. If you do not define the logger with getLogger(), each logger name will show up as root, making it difficult to discern which messages were logged by the uppermodule as opposed to the lowermodule. Messages that were logged from uppermodule.py list the __main__ module as the logger name, because uppermodule.py was executed as the top-level script.
Although we are now automatically capturing the logger name as part of the log format, both of these loggers are configured with the same basicConfig() line. In the next section, we’ll show you how to streamline your logging configuration by using fileConfig() to apply logging configuration across multiple loggers.
Use fileConfig() to output logs to multiple destinations
Although basicConfig() makes it quick and easy to get started with logging, using file-based (fileConfig()) or dictionary-based (dictConfig()) configuration allows you to implement more custom formatting and routing options for each logger in your application, and route logs to multiple destinations. This is also the model that popular frameworks like Django and Flask use for configuring application logging. In this section, we’ll take a closer look at setting up file-based logging configuration. A logging configuration file needs to contain three sections:
- [loggers]: the names of the loggers you’ll configure.
- [handlers]: the handler(s) these
loggersshould use (e.g.,consoleHandler,fileHandler). - [formatters]: the format(s) you want each logger to follow when generating a log.
Each section should include a comma-separated list of one or more keys: keys=handler1,handler2,[...]. The keys determine the names of the other sections you’ll need to configure, formatted as [<SECTION_NAME>_<KEY_NAME>], where the section name is logger, handler, or formatter. A sample logging configuration file (logging.ini) is shown below.
[loggers]
keys=root
[handlers]
keys=fileHandler
[formatters]
keys=simpleFormatter
[logger_root]
level=DEBUG
handlers=fileHandler
[handler_fileHandler]
class=FileHandler
level=DEBUG
formatter=simpleFormatter
args=("/path/to/log/file.log",)
[formatter_simpleFormatter]
format=%(asctime)s %(name)s - %(levelname)s:%(message)s
Python’s logging documentation recommends that you should only attach each handler to one logger and rely on propagation to apply handlers to the appropriate child loggers. This means that if you have a default logging configuration that you want all of your loggers to pick up, you should add it to a parent logger (such as the root logger), rather than applying it to each lower-level logger. See the documentation for more details about propagation. In this example, we configured a root logger and let it propagate to both of the modules in our application (lowermodule and uppermodule). Both loggers will output DEBUG and higher-priority logs, in the specified format (formatter_simpleFormatter), and append them to a log file (file.log). This removes the need to include logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(name)s %(levelname)s:%(message)s') in both modules.
Instead, once you’ve created this logging configuration file, you can add logging.config.fileConfig() to your code like so:
import logging.config
logging.config.fileConfig('/path/to/logging.ini', disable_existing_loggers=False)
logger = logging.getLogger(__name__)
Make sure to import logging.config so that you’ll have access to the fileConfig() function. In this example, disable_existing_loggers is set to False, indicating that the logging module should not disable pre-existing non-root loggers. This setting defaults to True, which will disable any non-root loggers that existed prior to fileConfig() unless you configure them afterward.
Your application should now start logging based on the configuration you set up in your logging.ini file. You also have the option to configure logging in the form of a Python dictionary (via dictConfig()), rather than in a file. See the documentation for more details about using fileConfig() and dictConfig().
Python exception handling and tracebacks
Logging the traceback in your exception logs can be very helpful for troubleshooting issues. As we saw earlier, logging.error() does not include any traceback information by default—it will simply log the exception as an error, without providing any additional context. To make sure that logging.error() captures the traceback, set the sys.exc_info parameter to True. To illustrate, let’s try logging an exception with and without exc_info:
# lowermodule.py
logging.config.fileConfig('/path/to/logging.ini', disable_existing_loggers=False)
logger = logging.getLogger(__name__)
def word_count(myfile):
try:
# count the number of words in a file, myfile, and log the result
[...]
except OSError as e:
logger.error(e)
logger.error(e, exc_info=True)
[...]
If you run the code with an inaccessible file (e.g., nonexistentfile.txt) as the input, it will generate the following output:
2019-03-27 21:01:58,191 lowermodule - ERROR:[Errno 2] No such file or directory: 'nonexistentfile.txt'
2019-03-27 21:01:58,191 lowermodule - ERROR:[Errno 2] No such file or directory: 'nonexistentfile.txt'
Traceback (most recent call last):
File "/home/emily/logstest/lowermodule.py", line 14, in word_count
with open(myfile, 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'nonexistentfile.txt'
The first line, logged by logger.error(), doesn’t provide much context beyond the error message (“No such file or directory”). The second line shows how adding exc_info=True to logger.error() allows you to capture the exception type (FileNotFoundError) and the traceback, which includes information about the function and line number where this exception was raised.
Alternatively, you can also use logger.exception() to log the exception from an exception handler (such as in an except clause). This automatically captures the same traceback information shown above and sets ERROR as the priority level of the log, without requiring you to explicitly set exc_info to True. Regardless of which method you use to capture the traceback, having the full exception information available in your logs is critical for monitoring and troubleshooting the performance of your applications.
Capturing unhandled exceptions
You’ll never be able to anticipate and handle every possible exception, but you can make sure that you log uncaught exceptions so you can investigate them later on. An unhandled exception occurs outside of a try...except block, or when you don’t include the correct exception type in your except statement. For instance, if your application encounters a TypeError exception, and your except clause only handles a NameError, it will get passed to any remaining try clauses until it encounters the correct exception type.
If it does not, it becomes an unhandled exception, in which case, the interpreter will invoke sys.excepthook(), with three arguments: the exception class, the exception instance, and the traceback. This information usually appears in sys.stderr but if you’ve configured your logger to output to a file, the traceback information won’t get logged there.
You can use Python’s standard traceback library to format the traceback and include it in the log message. Let’s revise our word_count() function so that it tries writing the word count to the file. Since we’ve provided the wrong number of arguments in the write() function, it will raise an exception:
# lowermodule.py
import logging.config
import traceback
logging.config.fileConfig('logging.ini', disable_existing_loggers=False)
logger = logging.getLogger(__name__)
def word_count(myfile):
try:
# count the number of words in a file, myfile, and log the result
with open(myfile, 'r+') as f:
file_data = f.read()
words = file_data.split(" ")
final_word_count = len(words)
logger.info("this file has %d words", final_word_count)
f.write("this file has %d words", final_word_count)
return final_word_count
except OSError as e:
logger.error(e, exc_info=True)
except:
logger.error("uncaught exception: %s", traceback.format_exc())
return False
if __name__ == '__main__':
word_count('myfile.txt')
Running this code will encounter a TypeError exception that doesn’t get handled in the try-except logic. However, since we added the traceback code, it will get logged, thanks to the traceback code included in the second except clause:
# exception doesn't get handled but still gets logged, thanks to our traceback code
2019-03-28 15:22:31,121 lowermodule - ERROR:uncaught exception: Traceback (most recent call last):
File "/home/emily/logstest/lowermodule.py", line 23, in word_count
f.write("this file has %d words", final_word_count)
TypeError: write() takes exactly one argument (2 given)
Logging the full traceback within each handled and unhandled exception provides critical visibility into errors as they occur in real time, so that you can investigate when and why they occurred. Although multi-line exceptions are easy to read, if you are aggregating your logs with an external logging service, you’ll want to convert your logs into JSON to ensure that your multi-line logs get parsed correctly. Next, we’ll show you how to use a library like python-json-logger to log in JSON format.
Unify all your Python logs
So far, we’ve shown you how to configure Python’s built-in logging library, customize the format and severity level of your logs, and capture useful information like the logger name and exception tracebacks. We’ve also used file-based configuration to implement more dynamic log formatting and routing options. Now we can turn our attention to interpreting and analyzing all the data we’re collecting. In this section, we’ll show you how to format logs in JSON, add custom attributes, and centralize and analyze that data with a log management solution to get deeper visibility into application performance, errors, and more.
Streamline your Python log collection and analysis with Datadog.
Log in JSON format
As your systems generate more logs over time, it can quickly become challenging to locate the logs that can help you troubleshoot specific issues—especially when those logs are distributed across multiple servers, services, and files. If you centralize your logs with a log management solution, you’ll always know where to look whenever you need to search and analyze your logs, rather than manually logging into each application server.
Logging in JSON is a best practice when centralizing your logs with a log management service, because machines can easily parse and analyze this standard, structured format. JSON format is also easily customizable to include any attributes you decide to add to each log format, so you won’t need to update your log processing pipelines every time you add or remove an attribute from your log format.
The Python community has developed various libraries that can help you convert your logs into JSON format. For this example, we’ll be using python-json-logger to convert log records into JSON.
First, install it in your environment:
pip install python-json-logger
Now update the logging configuration file (e.g., logging.ini) to customize an existing formatter or add a new formatter that will format logs in JSON ([formatter_json] in the example below). The JSON formatter needs to use the pythonjsonlogger.jsonlogger.JsonFormatter class. In the formatter’s format key, you can specify the attributes you’d like to include in each log record’s JSON object:
[loggers]
keys=root,lowermodule
[handlers]
keys=consoleHandler,fileHandler
[formatters]
keys=simpleFormatter,json
[logger_root]
level=DEBUG
handlers=consoleHandler
[logger_lowermodule]
level=DEBUG
handlers=fileHandler
qualname=lowermodule
[handler_consoleHandler]
class=StreamHandler
level=DEBUG
formatter=simpleFormatter
args=(sys.stdout,)
[handler_fileHandler]
class=FileHandler
level=DEBUG
formatter=json
args=("/home/emily/myapp.log",)
[formatter_json]
class=pythonjsonlogger.jsonlogger.JsonFormatter
format=%(asctime)s %(name)s %(levelname)s %(message)s
[formatter_simpleFormatter]
format=%(asctime)s %(name)s - %(levelname)s:%(message)s
Logs that get sent to the console (with the consoleHandler) will still follow the simpleFormatter format for readability, but logs produced by the lowermodule logger will get written to the myapp.log file in JSON format.
Once you’ve included the pythonjsonlogger.jsonlogger.JsonFormatter class in your logging configuration file, the fileConfig() function should be able to create the JsonFormatter as long as you run the code from an environment where it can import pythonjsonlogger.
If you’re not using file-based configuration, you will need to import the python-json-logger library in your application code, and define a handler and formatter, as described in the documentation:
from pythonjsonlogger import jsonlogger
logger = logging.getLogger()
logHandler = logging.StreamHandler()
formatter = jsonlogger.JsonFormatter()
logHandler.setFormatter(formatter)
logger.addHandler(logHandler)
To see why JSON format is preferable, particularly when it comes to more complex or detailed log records, let’s return to the example of the multi-line exception traceback we logged earlier. It looked something like this:
2019-03-27 21:01:58,191 lowermodule - ERROR:[Errno 2] No such file or directory: 'nonexistentfile.txt'
Traceback (most recent call last):
File "/home/emily/logstest/lowermodule.py", line 14, in word_count
with open(myfile, 'r') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'nonexistentfile.txt'
Although this exception traceback log is easy to read in a file or in the console, if it gets processed by a log management platform, each line may show up as a separate log (unless you configure multiline aggregation rules), which can make it difficult to reconstruct exactly what happened.
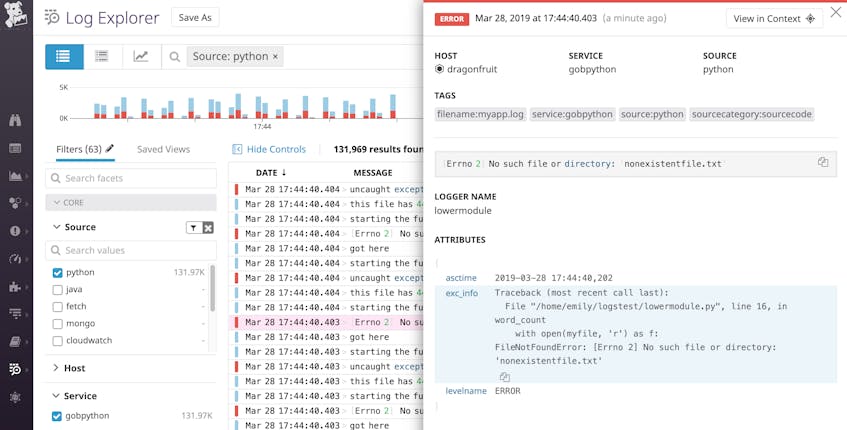
Now that we’re logging this exception traceback in JSON, the application will generate a single log that looks like this:
{"asctime": "2019-03-28 17:44:40,202", "name": "lowermodule", "levelname": "ERROR", "message": "[Errno 2] No such file or directory: 'nonexistentfile.txt'", "exc_info": "Traceback (most recent call last):\n File \"/home/emily/logstest/lowermodule.py\", line 19, in word_count\n with open(myfile, 'r') as f:\nFileNotFoundError: [Errno 2] No such file or directory: 'nonexistentfile.txt'"}
A logging service can easily interpret this JSON log and display the full traceback information (including the exc_info attribute) in an easy-to-read format:
Add custom attributes to your JSON logs
Another benefit of logging in JSON is that you can add attributes that an external log management service can parse and analyze automatically. Earlier we configured the format to include standard attributes like %(asctime)s, %(name)s, %(levelname)s, and %(message)s. You can also log custom attributes by using the python-json-logs “extra” field. Below, we created a new attribute that tracks the duration of this operation:
# lowermodule.py
import logging.config
import traceback
import time
def word_count(myfile):
logger = logging.getLogger(__name__)
logging.fileConfig('logging.ini', disable_existing_loggers=False)
try:
starttime = time.time()
with open(myfile, 'r') as f:
file_data = f.read()
words = file_data.split(" ")
final_word_count = len(words)
endtime = time.time()
duration = endtime - starttime
logger.info("this file has %d words", final_word_count, extra={"run_duration":duration})
return final_word_count
except OSError as e:
[...]
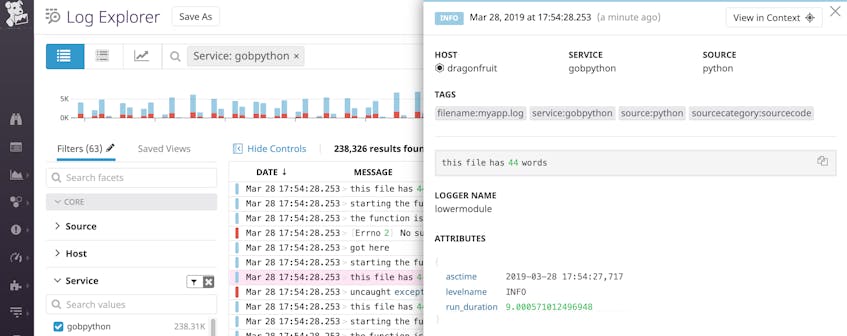
This custom attribute, run_duration, measures the duration of the operation in seconds:
{"asctime": "2019-03-28 18:13:05,061", "name": "lowermodule", "levelname": "INFO", "message": "this file has 44 words", "run_duration": 6.389617919921875e-05}
In a log management solution, this JSON log’s attributes would get parsed into something that looks like the following:
If you’re using a log monitoring platform, you can graph and alert on the run_duration of your application over time. You can also export this graph to a dashboard if you want to visualize it side-by-side with application performance or infrastructure metrics.
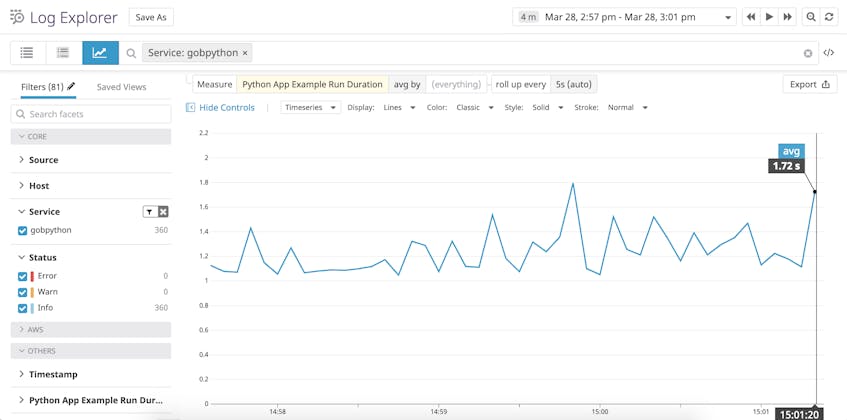
Whether you’re using python-json-logger or another library to format your Python logs in JSON, it’s easy to customize your logs to include information that you can analyze with an external log management platform.
Correlate logs with other sources of monitoring data
Once you’re centralizing your Python logs with a monitoring service, you can start exploring them alongside distributed request traces and infrastructure metrics to get deeper visibility into your applications. A service like Datadog can connect logs with metrics and application performance monitoring data to help you see the full picture.
For example, if you update your log format to include the dd.trace_id and dd.span_id attributes, Datadog will automatically correlate logs and traces from each individual request. This means that as you’re viewing a trace, you can simply click on the “Logs” tab of the trace view to see any logs generated during that specific request, as shown below.
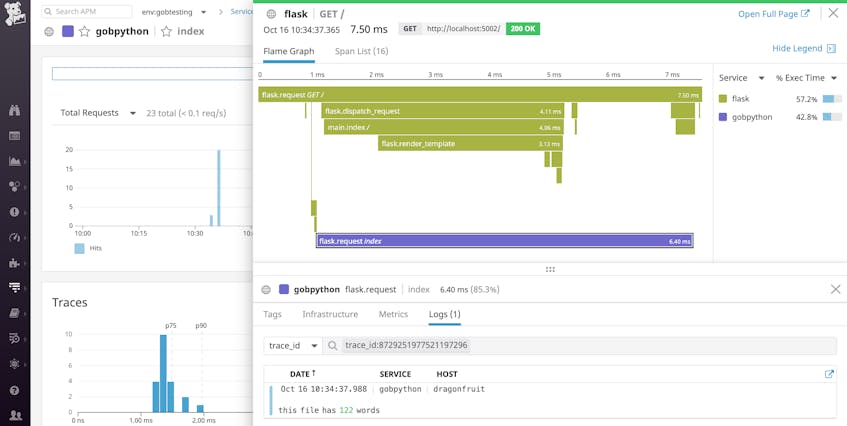
You can also navigate in the other direction—from a log to the trace of the request that generated the log—if you need to investigate a specific issue. See our documentation for more details about automatically correlating Python logs and traces for faster troubleshooting.
Centralize and analyze your Python logs
In this post we’ve walked through some best practices for configuring Python’s standard logging library to generate context-rich logs, capture exception tracebacks, and route logs to the appropriate destinations. We’ve also seen how you can centralize, parse, and analyze your JSON-formatted logs with a log management platform whenever you need to troubleshoot or debug issues. If you’d like to monitor your Python application logs with Datadog, sign up for a free trial.
